I dati come nuovo petrolio. Pochi modi di dire hanno avuto, nella prima fase del digitale, una fortuna paragonabile a questa metafora. Ha aiutato un’intera generazione di manager a capire che i dati non erano un sottoprodotto delle operazioni, ma una risorsa strategica da proteggere e da raffinare. L’ho usata anch’io, per anni, e in quel momento serviva. Applicata all’AI di oggi, però, comincia a confondere più di quanto chiarisca, perché suggerisce un’equivalenza che non regge: il petrolio è prezioso in quanto materia, basta estrarlo per averne valore. I dati, nell’AI applicata, non hanno valore in quanto materia. Hanno valore in quanto contesto, e tra le due cose c’è uno scarto che molte aziende stanno scoprendo a proprie spese.
Da zero a loop
Dai dati al contesto: la nuova frontiera AI del vantaggio competitivo aziendale
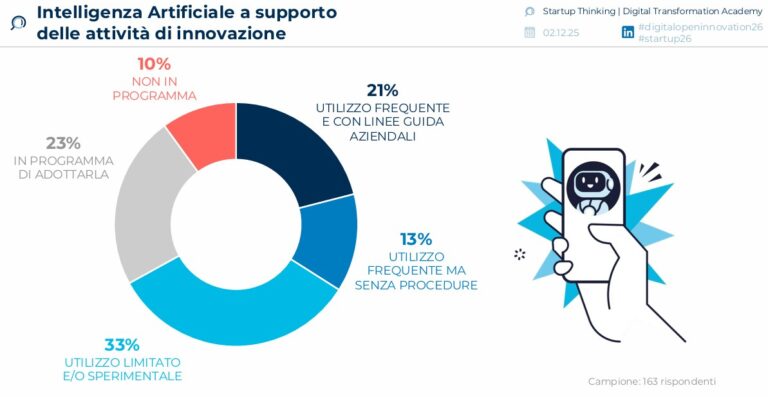
La metafora dei dati come nuovo petrolio è familiare a una generazione di manager. Ma, applicata all’AI di oggi, confonde più di quanto chiarisca. Il 49% delle aziende lo scopre quando il primo progetto AI si arena. Ecco come un’organizzazione può gestire al meglio il processo e chi lo guida
Pubblicato il 2 giu 2026
Fabio Lalli
Imprenditore, advisor e docente

@RIPRODUZIONE RISERVATA


Fabio Lalli
Imprenditore, advisor e docente
Imprenditore, advisor e docente, è da anni impegnato sui temi dell’innovazione e della trasformazione digitale. Nel suo saggio “Pelle Digitale” (2026) indaga il rapporto tra tecnologia, conoscenza e identità organizzativa
Continua a leggere questo articolo



L’intelligenza artificiale per l’innovazione

Tutti
AI & INNOVAZIONE
CHE COS'È INNOVERAI
Che cos'è InnoverAI
AI & STARTUP
AI TRANSFORMATION
Filtra per topic















INNOVATION LEADER
-

Intervista con Valeria de Flaviis (CDP): “L’AI è uno dei migliori alleati per chi fa innovazione. Ecco perché”
15 Lug 2026 -
Paolo Costa (Spindox): “Un agente AI lavora come Superman, ma non basta ammirarlo per creare valore”
10 Lug 2026 -
Matteo Musa (Fitprime): “Con la disciplina da rugbista ho fatto impresa senza spezzarmi”
07 Lug 2026 -
Tommaso Carboni: “Per vendere auto non basta più un sito e vi spiego perché”
01 Lug 2026 -
Uljan Sharka 10 anni dopo, la storia dell’imprenditore che guida la sfida dell’AI europea
25 Giu 2026